from numba import njit import numpy as np import time from sklearn.linear_model import LinearRegression
先来一个函数,他是使用skLearn库的LinearRegression实现的:
1 2 3 4 5 6
defloop_reg_sklearn(): for i inrange(10000): x = np.random.random((100,8)) x = np.concatenate([x,np.ones((100,1))], axis=1) y = np.random.random((100,1)) reg = LinearRegression().fit(x, y)
再用numpy实现一下:
1 2 3 4 5 6
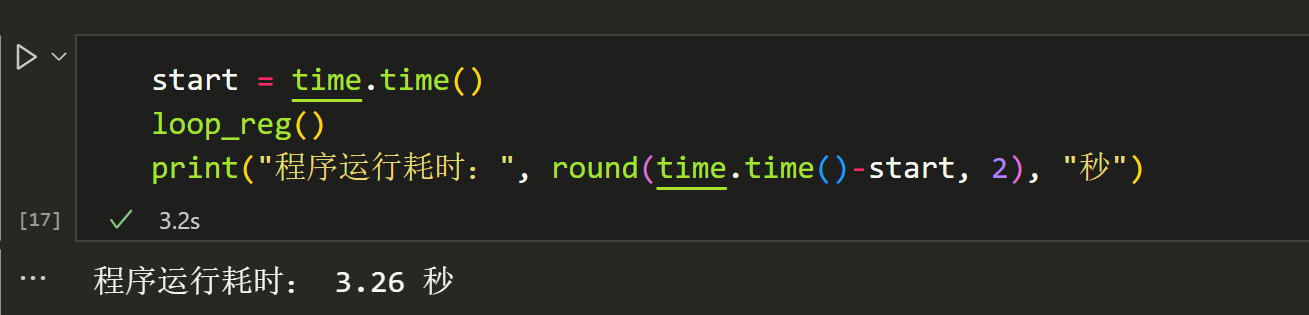
defloop_reg(): for i inrange(10000): x = np.random.random((100,8)) x = np.concatenate([x,np.ones((100,1))], axis=1) y = np.random.random((100,1)) beta = np.dot(np.dot(np.linalg.inv(np.dot(x.T,x)),x.T), y)
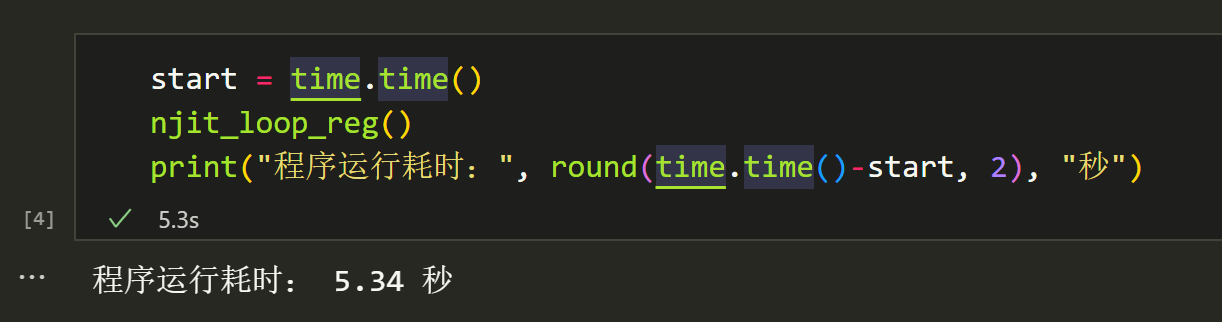
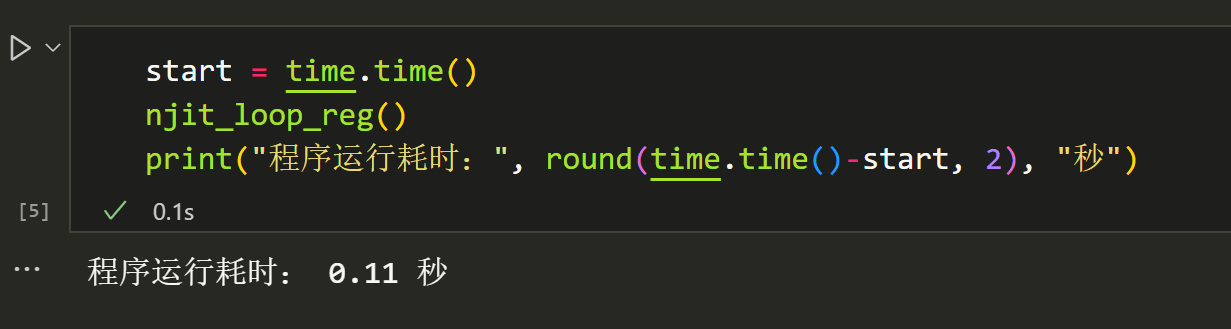
@njit defnjit_loop_reg(): for i inrange(10000): x = np.random.random((100,8)) x = np.concatenate([x,np.ones((100,1))], axis=1) y = np.random.random((100,1)) beta = np.dot(np.dot(np.linalg.inv(np.dot(x.T,x)),x.T), y)


 wechat
wechat alipay
alipay








